声明:本文来源于微信公众号 AIGC开放社区(ID:AIGCOPEN),作者:AIGC开放社区,授权站长之家转载发布。
12月8日,着名Stabilityty,开源生成AI平台.Ai在官网开源,StableLML,30亿参数的大语言模型 Zephyr3B。
Zephyr3B专门用于手机、笔记本电脑等移动设备,具有参数小、性能强、计算能力消耗低的特点,可自动生成文本、总结摘要等,可与70亿、130亿参数的模型相媲美。
值得一提的是,该模型的核心结构来自Zephyr7B,并进行了精调。Zephyr7B基于Mistral,几天前刚刚获得35亿元的巨额融资 AI的Mistral-微调7B模型。
同时,使用GPT-3.5生成训练数据集和GPT-4进行人工智能反馈。因此,Zephyr3B有许多大型工厂模型基因超级缝合怪。
Zephyr3B开源地址:https://huggingface.co/stabilityai/stablelm-zephyr-3b
Zephyr7B开源地址:https://huggingface.co/HugingFaceH4/zephyr-7b-beta
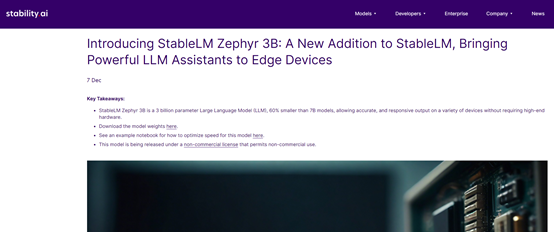
由于Stability.Ai没有打开Zephyr3B的论文,只能从Zephyr7B的技术文档中解读其核心结构,主要包括监督学习优化、人工智能反馈和直觉优化指导学习三个模块。
由于该模型在训练数据集和人工智能反馈方面采用了GPT系列模型,因此具有强大的ChatGPT基因。
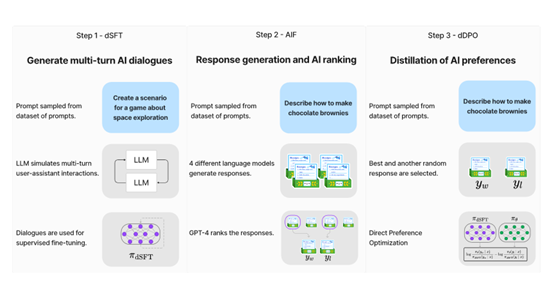
监督学习优化(dSFT)
通过OpenAIGPT-3.5模型,研究人员生成了大型对话数据集“UltraChat多轮不同主题对话的例子超过147万个。
然后通过数据集对模型进行监督、学习和优化。训练样本是对话内容和回复最大降低“交叉熵”误差。
该过程类似于传统的监督学习方法,将模型训练任务指定到给定的数据集。
但不同于人工数据集的使用,该方法直接使用强大的语言模型生成高质量的训练数据,避免人工乱标问题。
人工智能反馈(AIF)
为了进一步提高模型文本生成和理解的准确性,研究人员使用第二个数据集Ultrafeedback在不同主题下对四个不同的大语言模型进行评分和评价。

具体方法是将每次对话的文本提示发送到4个模型,得到4个答案,然后通过“教师模型”GPT-4打分(0-10分)。最高分答案为“优先答案”,随机选择另一个作为“非优先答案”进行深度优化。
直觉优化指导学习(dDPO)
使用前面的“”UltraFeedback以GPT-4对话样本和质量评价为数据配对组,提取高分和低分样本。
通过反向传播优化模型参数,计算优先和非优先样本的概率,并利用损失函数测量其差异。

该算法以试批的方式运行,在每轮中随机选择样本对,计算当前模型和基线模型在这两个样本中的概率误差。
通过这种反向传输,误差可以追溯到参数,模型结构可以实时微调。整个优化过程非常高效,可以在几个小时内完成,无需任何人工标记。
测试数据
Stability.Ai说Zephyr3B在MT Bench、Alpacaeval等平台进行了测试,在生成上下文相关性、连贯性和语言准确性方面表现出色。
它特别擅长创造性和个性化的文本生成,可以根据用户输入的数据进行分析。
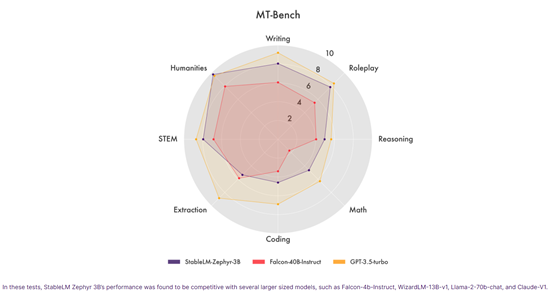
Falcon-4b的性能-Instruct、WizardLM-13B-v1、Llama-2-70b-chat 和 Claude-V1等大参数模型相当。
Copyright © 2013-2025 bacaiyun.com. All Rights Reserved. 八彩云 版权所有 八彩云(北京)网络科技有限公司 京ICP备2023023517号
本站文章全部采集于互联网,如涉及版权问题请联系我们删除.联系QQ:888798,本站域名代理为阿里云
