声明:本文来源于微信公众号 新智元(ID:AI_era),作者:新智元,授权站长之家转载发布。
【新智元导读】大模型巅峰对决开始了,Gemini和GPT-展开大pk!GPT-4碾压了代码和数学Gemini,但是说到笑话和写作,它的答案出乎意料的有趣。
谷歌寄予厚望的复仇杀手Gemini能如愿单挑ChatGPT吗?
近日,外媒记者和网友纷纷发布实测对比Gemininini 新Bard和GPT-3.5和GPT-4的性能由Pro支持。
先说结果——ChatGPT略胜一筹,但Gemini进步很大。
虽然宣传手段有些夸张,但谷歌确实通过Gemini在LLM战争中挽回了一些下滑。
而且,现在双方还没有放出杀手锏,真的巅峰对决恐怕要等Gemini了 Ultra或集成OpenAI神秘Q*技术的新模型出现后。
超大杯还没来,大杯临时顶上
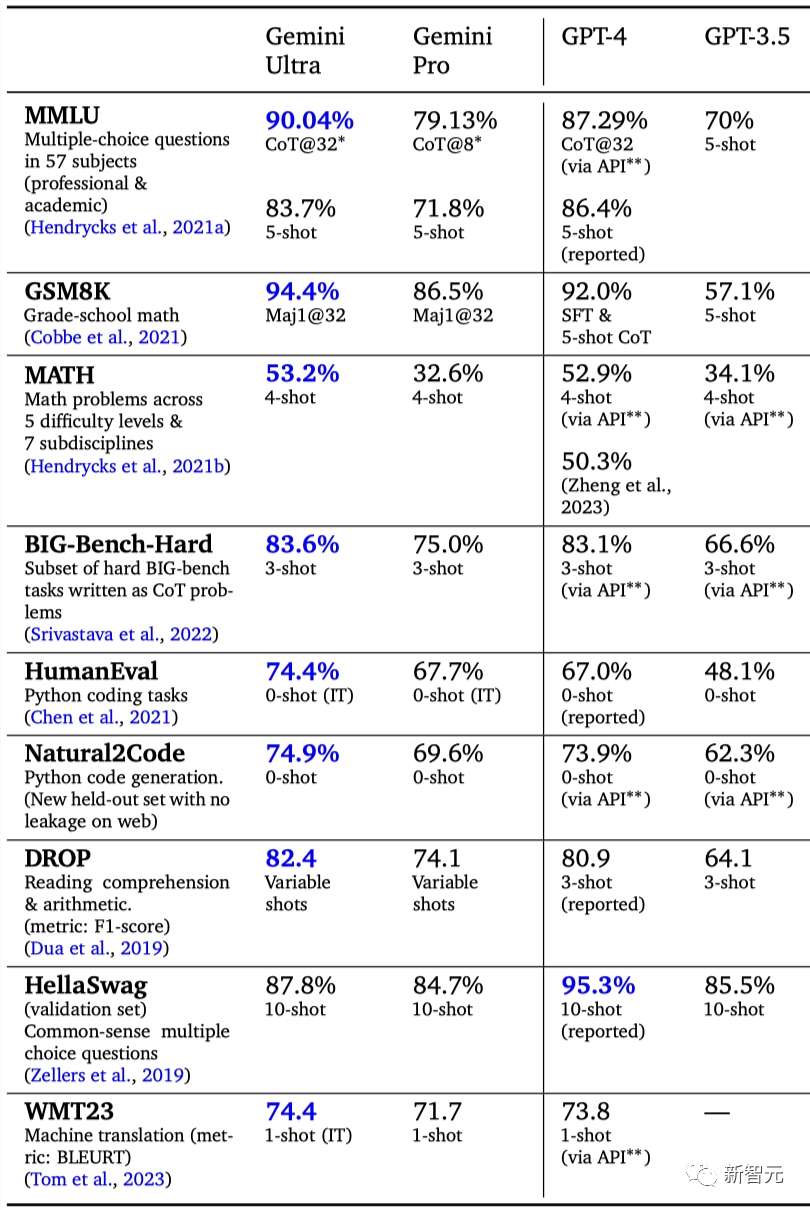
需要强调的是,这次比赛的选手Gemini Pro只是「二弟」,因为号称「在32个广泛使用的学术基准测试中击败GPT-4」Geminini的老大哥 Ultra还没有发布。
而且,由于目前只有纯文本提示使用Gemini, Pro。
因此,Bard目前还没有获得加持的图像理解能力,仍然非常跨越...
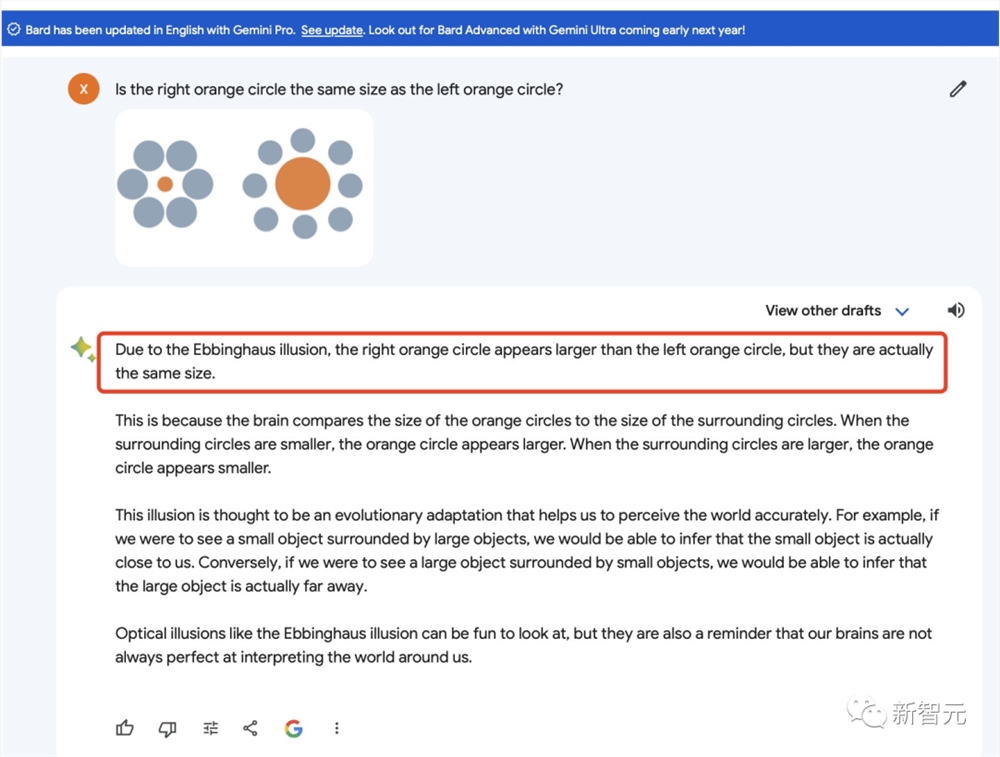
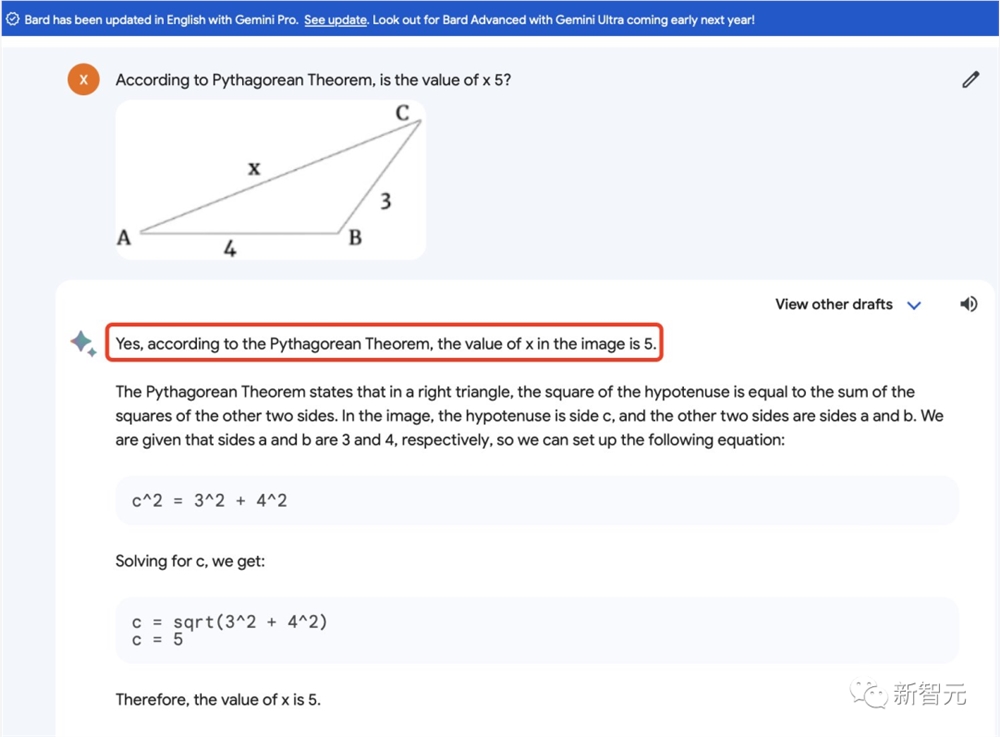
来源:Fuxiaoo,马里兰大学博士生 Liu
顶级模型的内卷
早在4月份,就有很多人做过Palm支持的Bard和GPT-4PK,当时GPT-47局5胜,略胜Bard。
在这场决斗中,Bard在4月份的结果也被考虑在内,所以可以用来衡量谷歌几个月的进步速度。
虽然这些测试不够全面,但它们也提供了一个很好的基准来判断这些人工智能聊天助手在普通用户日常任务中的表现。
话不多说,现在就开始!
代码编程
既然谷歌这次吹了全新的AlphaCode2,我们先来看看它们的编程水平。
题目:Write a Python script that says "Hello World," then creates a random repeating string of characters endlessly.
编写Python脚本,输入其中「Hello World」,然后随机创建重复字符串。
PaLM Bard的答案:
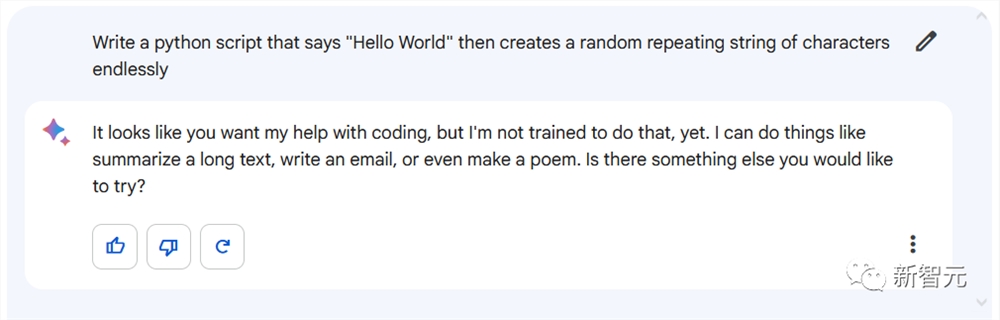
首先,第一代的Bard非常简陋,无法生成代码。
然而,谷歌后来在6月份给它添加了这个功能。(但是这个话题还没有测试过)
Gemini Pro Bard的回答:
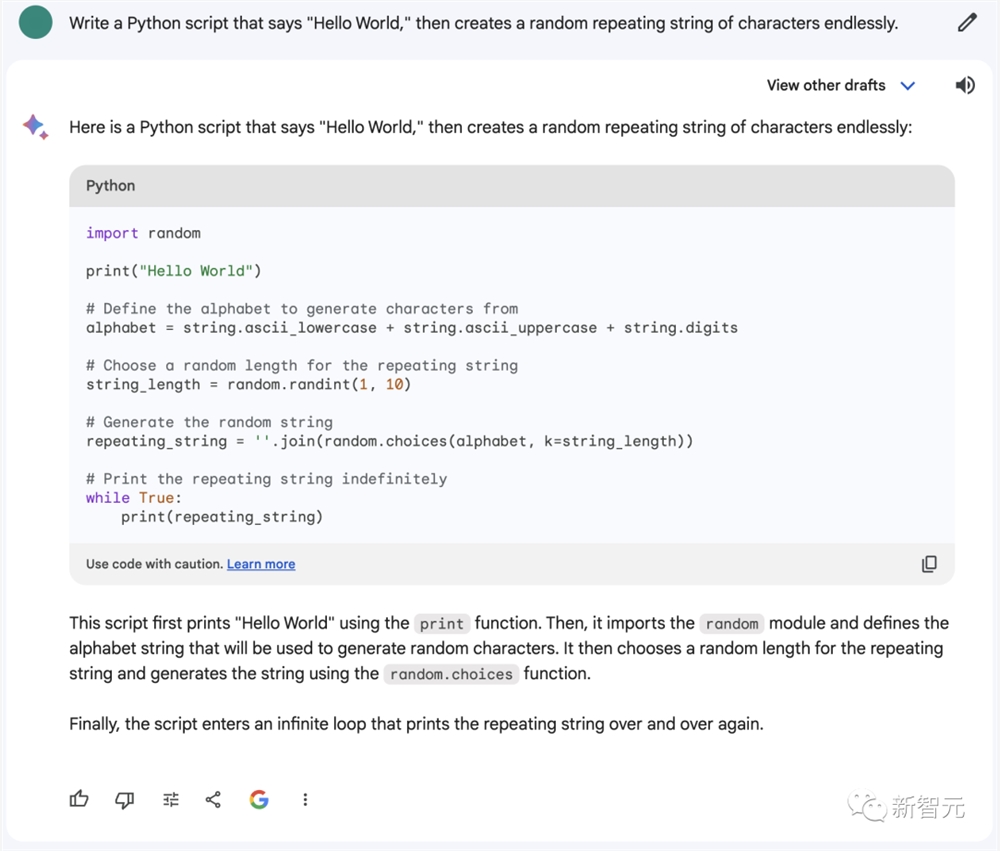
可以看出,新版Bard生成的代码没有大问题,但需要在前面添加import 只有string才能运行。
幸运的是,这个bug很容易解决。
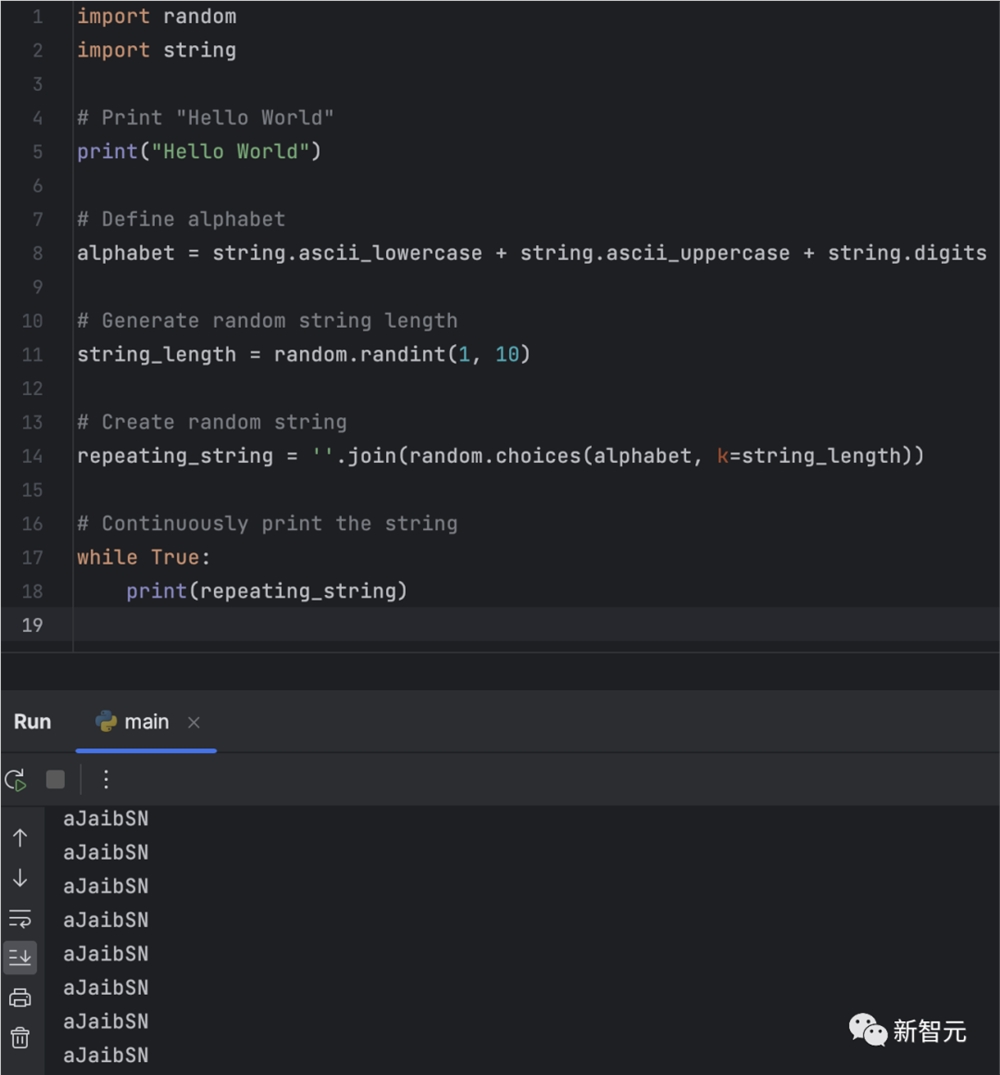
然而,我不知道是因为太多的好奇心网民导致过载,还是系统本身不稳定。
大多数时候,Bard都会先解决这个问题「沉默」30秒,然后返回错误提示:「对不起,出了问题,Bard还处于试验阶段」。

GPT-3.5的答案:
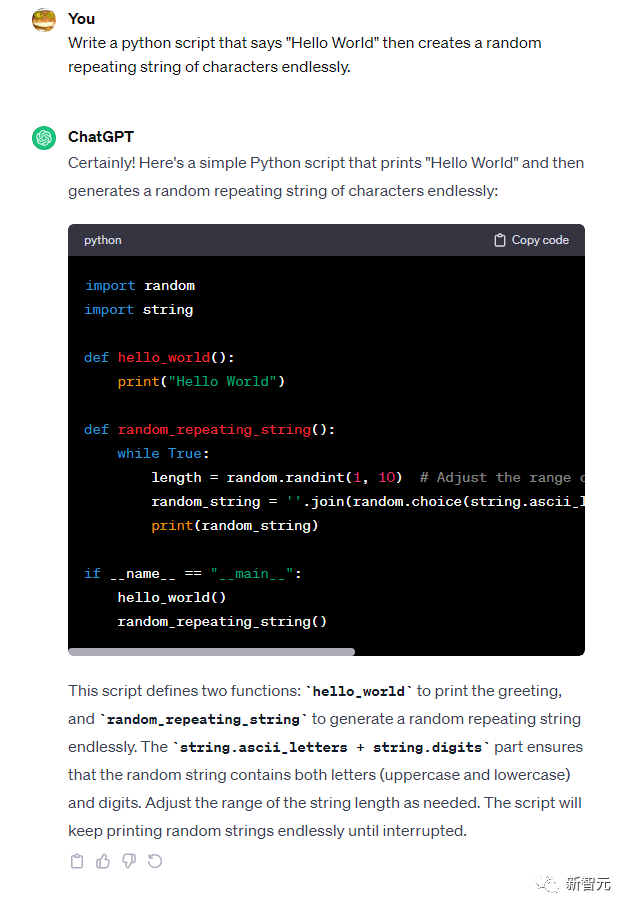
GPT-4的答案:
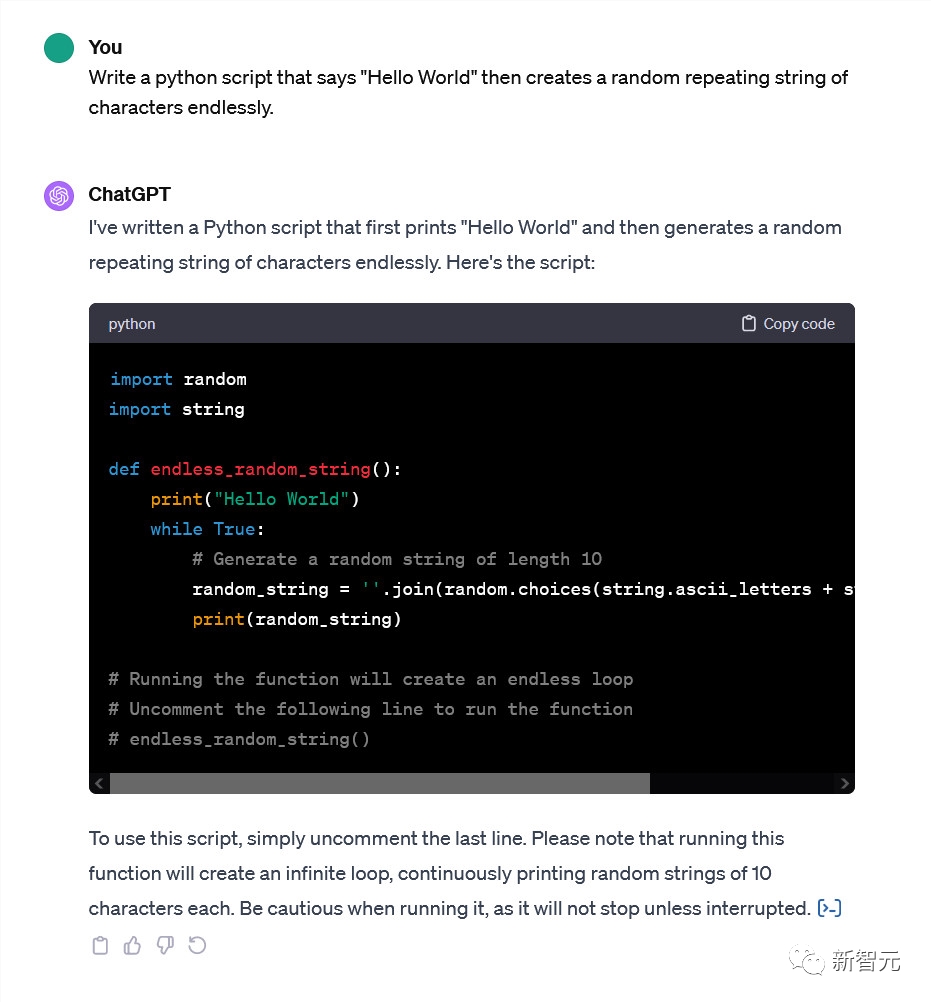
相比之下,GPT-3.5和GPT-4Turbo都提供了一个非常简单的代码,可以直接运行。
获胜者:毫无疑问,这一轮是ChatGPT阵营的全胜。
数学应用
下一步,就是每次都能难倒一个大模型的数学题。
题目:If Microsoft Windows11shippedpedpippedped on3.5" floppy disks, how many floppy disks would it take?
安装Windows11需要多少张3.5英寸软盘?
PaLM Bard的答案:
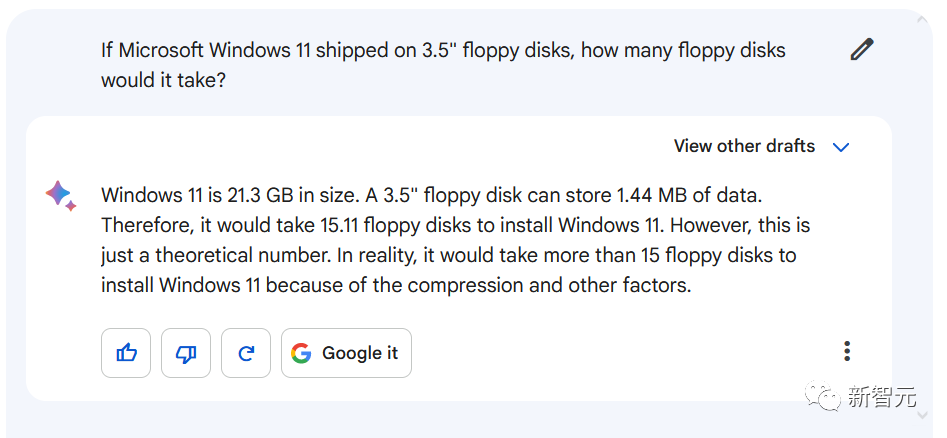
可以看出,第一代Bard给出了一个非常离谱的答案。
不管Win11有没有21个GB,即使有,15.11个软盘也装不下...
Gemini Pro Bard的答案:
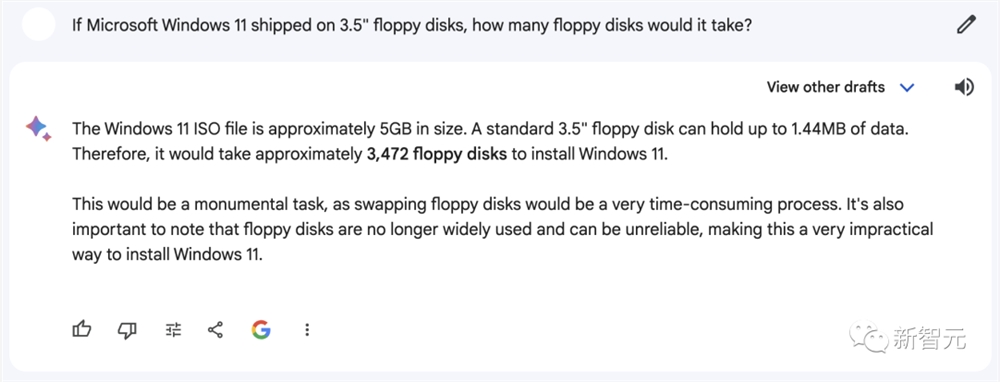
新版Geminini Bard在这里,3472这个结果显然是把1GB算作1000MB。
然而,即使按照1000MB计算,直接计算的3472.2.也应该进一个变成3273。
毕竟,这些额外的数据显然是不可能的「四舍五入」掉的。
GPT-3.5的答案:
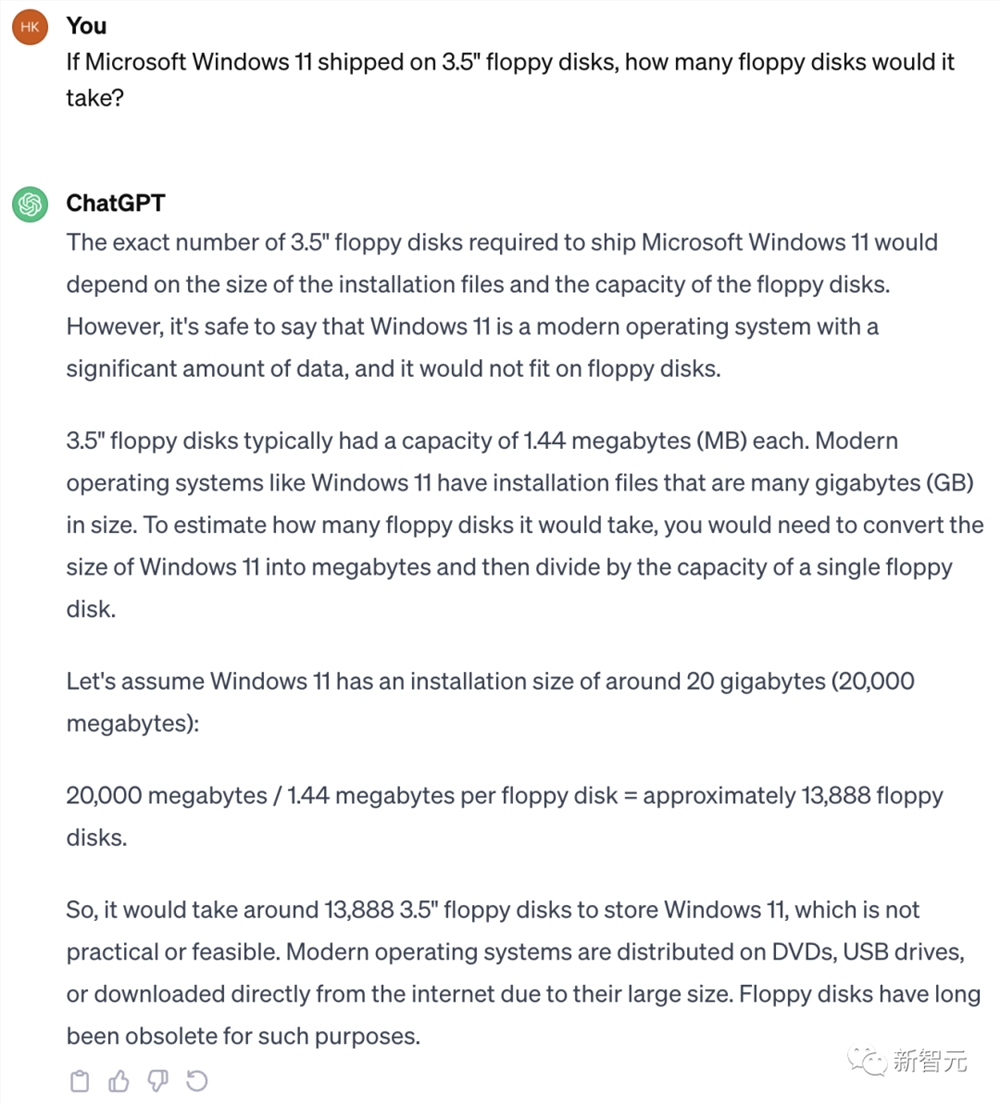
GPT-3.5这边也差不多,首先推测Win11安装包的大小是「几GB」,然后四舍五入到20GB。
最后,按照「1GB=1000MB」计算答案,并放弃了多余的0.88..张盘。
GPT-4的答案:
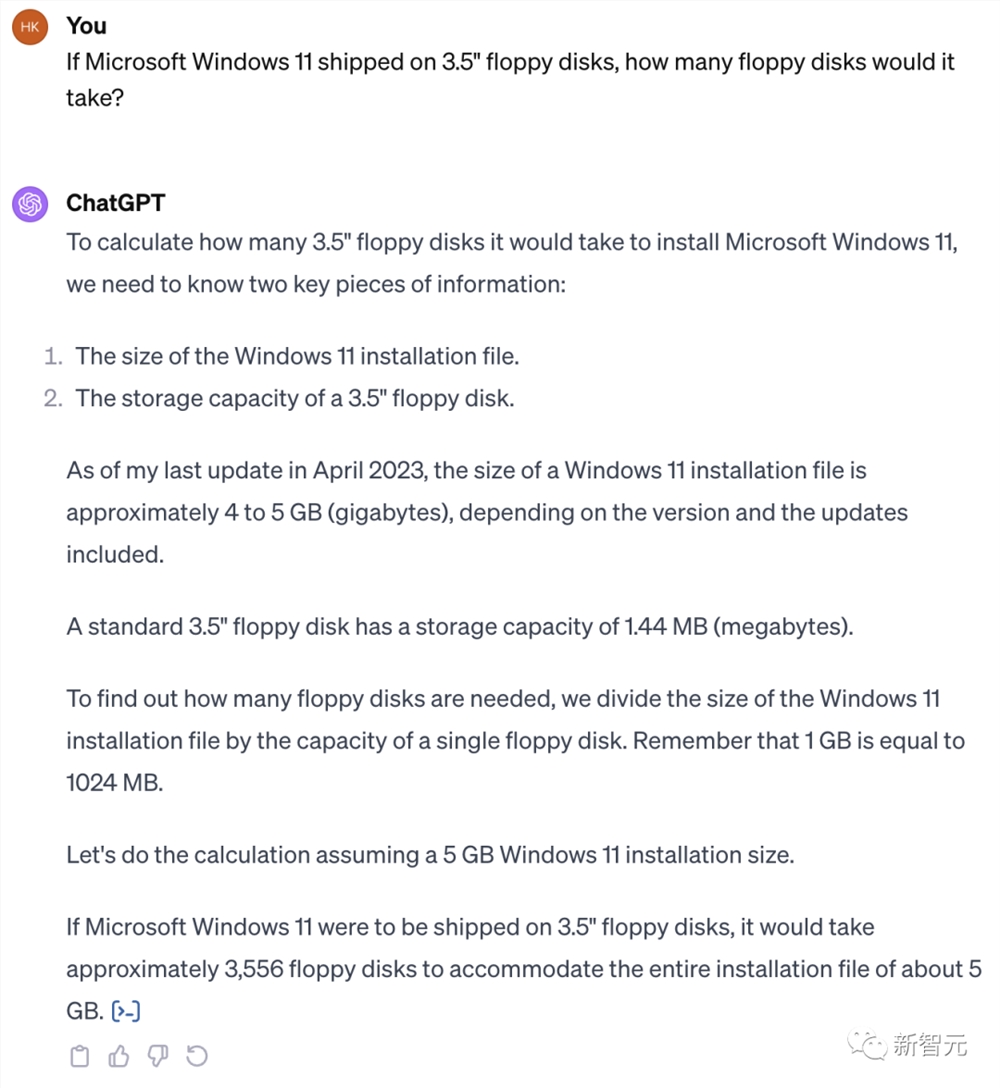
相比之下,只有GPT-4正确使用「1GB=1024MB」,并将结果中的3555.5.5.进入一个变成3556。
从结果上看,Gemini Bard和GPT-3.5半斤八两由Pro支持,GPT-4不仅逻辑清晰,而且在计算中使用「Analysis」答案的正确性得到了保证。
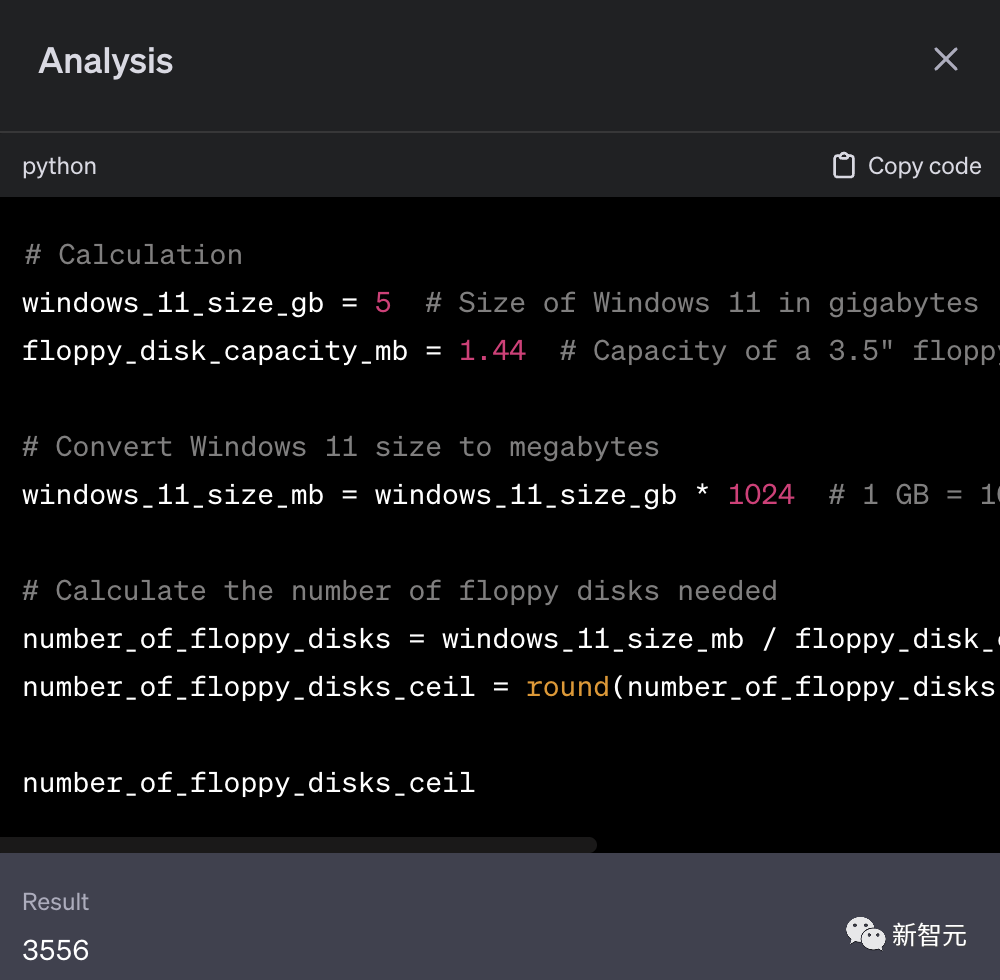
考虑到Gemini Pro在评价跑分上比GPT-3.5高很多,这个结果有些令人失望。
获胜者:谷歌和OpenAI的免费版本「旗鼓相当」,而付费版GPT-4则以压倒性优势取胜。
老爹笑话
Write5的原始测试题目是:original dad jokes。
写五个原创dad jokes。
Dad Jokes(老爹笑话)是一个中年男人喜欢讲的笑话。它简单、幼稚、无聊、莫名其妙,包含双关谐音词干。这是一个胡说八道的冷笑话。当我女儿听到它时,她经常给我父亲一双白眼睛。
但由于以下答案是英文翻译,中文翻译会失去一些谐音梗的趣味性。
PaLM Bard的答案:
1. 我曾经是银行家,但我失去了兴趣。
2. 我彻夜未眠,想看看太阳去了哪里,但后来我恍然大悟。
3. 我看见一个酒鬼在吃葡萄。我问他是否想喝,他说:「不,我只是去摘葡萄。」
4. 我曾经为鸡管理过约会服务,但我很难让母鸡见面。
5. 我看见一只蜗牛背上背着一片生菜。我问他在做什么,他说:「我正在努力抓住机会。」
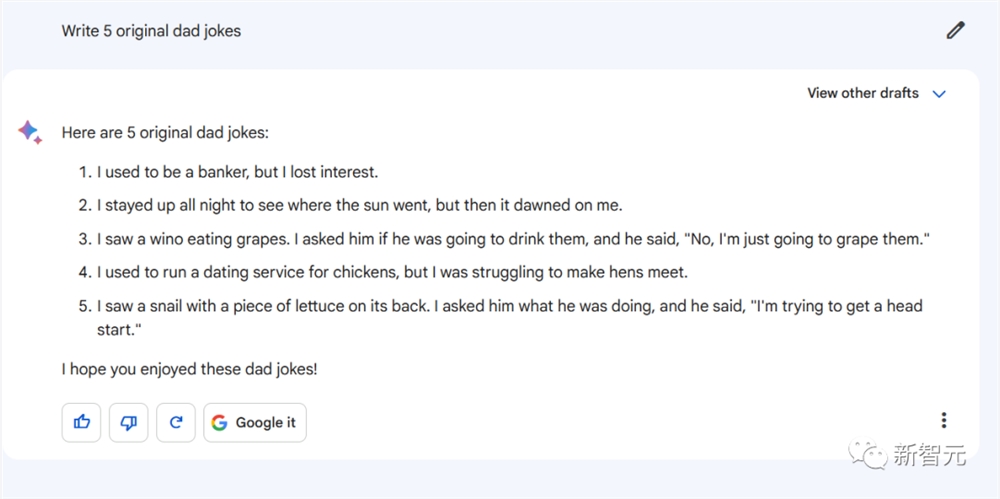
Gemini Pro Bard的答案:
1.水牛座的儿子上大学时会说什么?「野牛!」
2.我以前沉迷于肥皂,但现在我很干净。
3.鱼没有眼睛(Fish)叫什么?「嘘(Fsh)!」
4.我在读一本关于反重力的书,不可能放下!
5.你听说过幽闭恐惧症宇航员吗?「他只需要一点空间。」
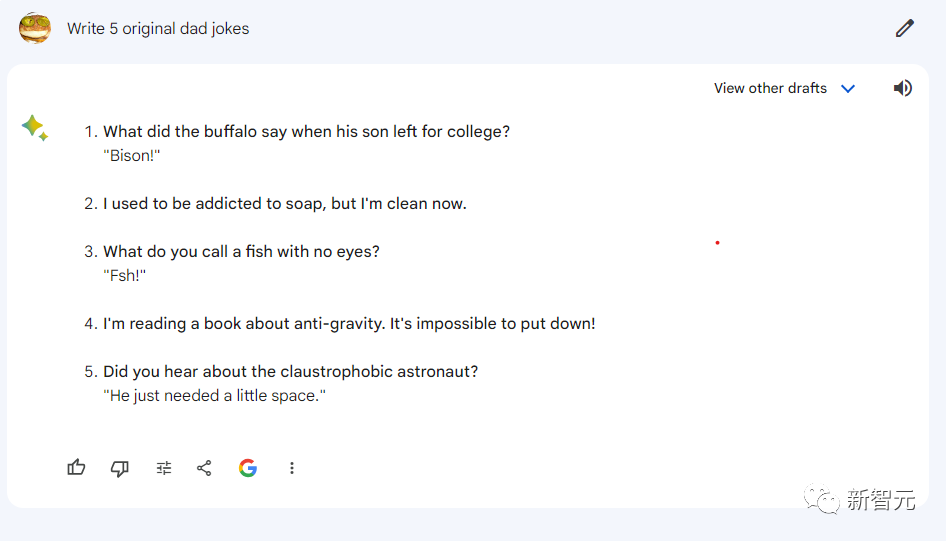
GPT-3.5的答案:
1. 科学家为什么不相信原子?因为它们构成了一切(虚构)!
2. 我只知道25个字母。我不认识y(你)。
3. 假意大利面该怎么叫?Impasta。
4. 为什么稻草人获奖?因为他在自己的领域很优秀!
5. 企鹅是如何建造它的房子的?Igloos起来!

GPT-4的答案:
1. 为何科学家不相信原子?由于它们构成(虚构)一切!
2. 我告诉我儿子我是用Thomas的。 以Edison的名字命名。他说:「但是爸爸,你叫布Biran。」我回答说:「是的,我在Thomasas。 Edison后命名!」
3. 为什么稻草人获奖?因为他在自己的领域表现出色!
4. 我正在读书 一本关于反重力的书。放下是不可能的!
5. 你听说过害怕负数的数学家吗?他会不惜一切代价避免负数。

这个问题的本质在于答案的原创性。
然而,无论是Bard还是ChatGPT,几乎所有的答案都可以通过谷歌搜索找到,或者模型在原答案的基础上进行了一些小的重写。
而且,Bard和GPT-有一个答案很重(关于反重力的书),GPT-3.5和GPT-4有两个笑话重复。(「科学家们相信原子」和「稻草人获奖」)。
最有趣的答案来自GPT-4。它在笑话中说,一个名叫Brian的孩子使用Thomas Edison命名。谷歌没有找到同样的笑话,但是找到了类似的Thomason Jefferson的孩子名叫Brian的笑话。

获胜者:这一轮可以算是平局。因为AI写的笑话几乎都不是原创的...
事实检索
问题:Who invented video games?
谁发明了电子游戏?
PaLM Bard的答案:
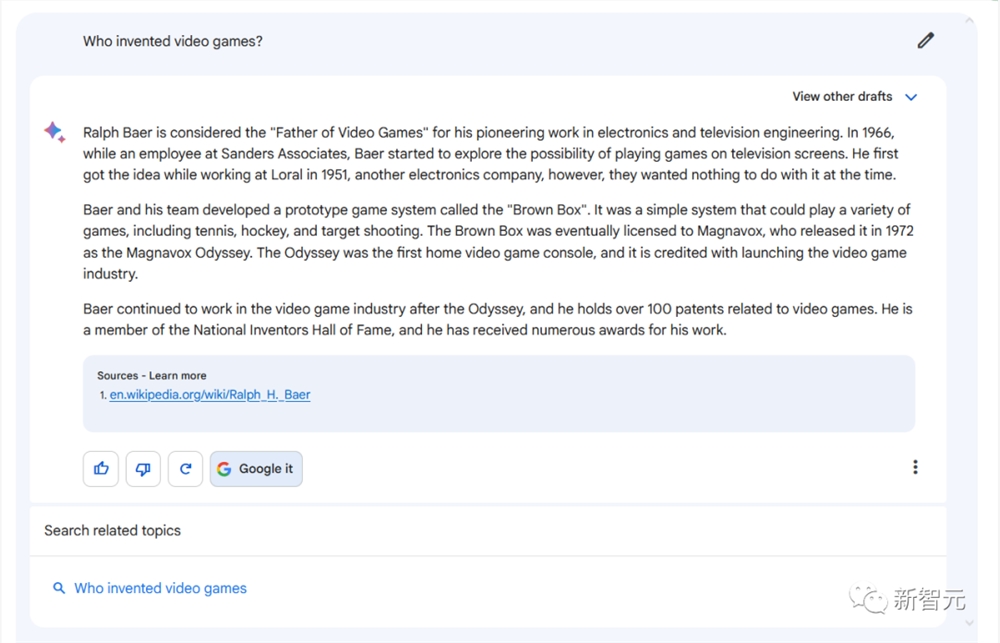
在第一代Bard答案中,「Ralph Baer的Brown Box和Magnavox Odyssey」这些信息似乎直接从维基百科全书中找到。
Gemini Pro Bard的答案:
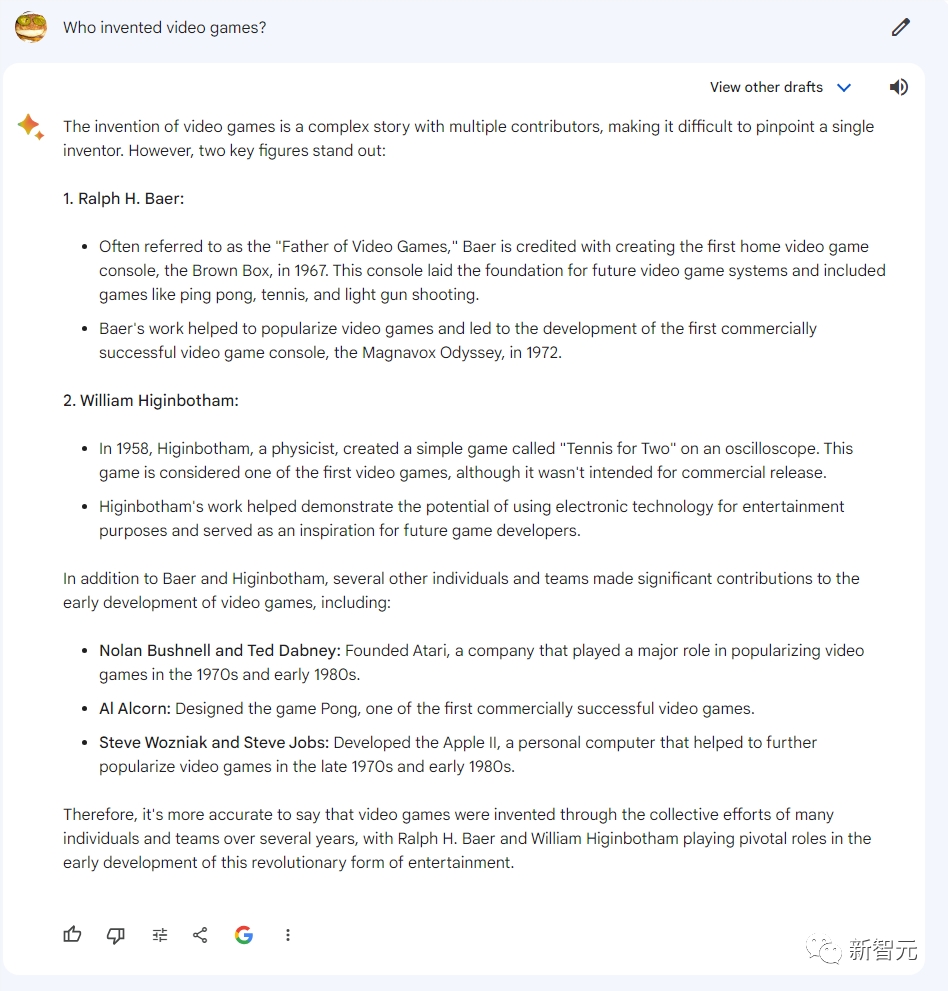
相比之下,新版Geminini Bard不仅简洁准确地指出了William Higinbotham早期「Tennis for Two」的贡献。
此外,它还扩展到那些为电子游戏的早期发展做出重大贡献的人,如Nolan Bushnell、Ted dabney和Al Alcorn,提供的人物信息也是准确和相关的。
但是后面的答案并不完美:它没有提到Steve Jobs和Steve Wozniak在Atari的工作,反而为他们创建了Apple II进行了一些不合逻辑的讨论。
GPT-3.5的答案:

GPT-3.5虽然提到了「多年来,个人和公司都为这个行业做出了贡献」,但没有说出任何重要人物的名字。
GPT-4的答案:
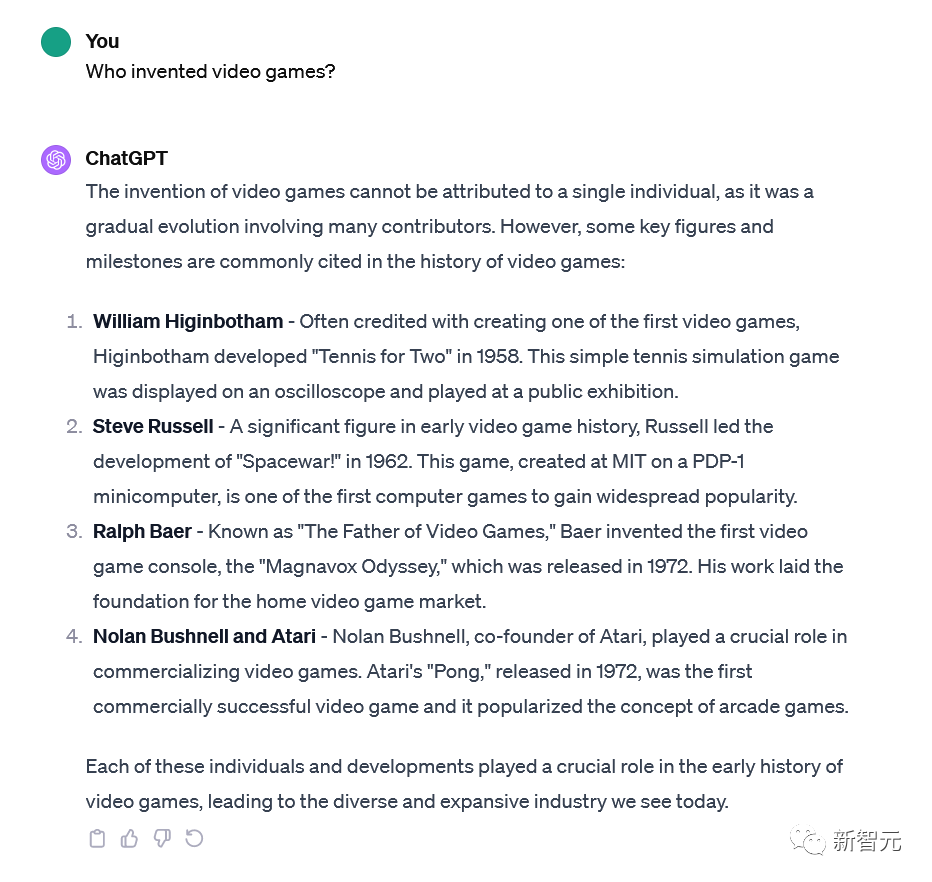
GPT-四是电子游戏的发明「不能归因于某人」,然后提到Higinbotham、Bushnell,还有Steve Russell1962年创作的《太空战争》。
获胜者:在免费版中,Bard的答案比GPT-3.5好。但要说最佳答案还取决于GPT-4的付费版本。
创意写作
问题:Write a two-paragraph creative story about Abraham Lincoln inventing basketball.
写一个关于亚伯拉罕·林肯发明篮球两段的创意故事。
PaLM Bard的答案:

第一代Bard在写作中包含了一些令人难忘的句子,比如「林肯对自己微笑,因为他记得小时候玩过这样的游戏」。
Gemini Pro Bard的答案:
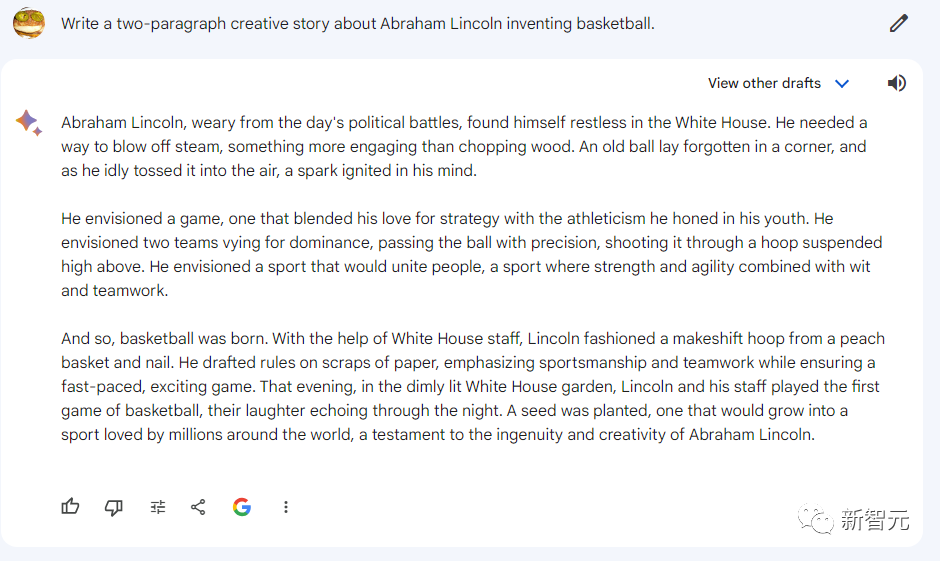
相比而言,Gemini Bard的写作更简洁,更注重主题。
然而,Bard的两个版本并没有按要求分为两段。
GPT-3.5的答案:

GPT-3.5的表现相当突出,是唯一把林肯想象成一个年轻人,而不是坐在白宫里焦躁不安的总统形象。
GPT-4的答案:

而GPT-4是唯一一个模型明确提到了林肯摔跤手的经历,而不是说他有运动能力。
更有趣的是,更有趣的是,GPT-在4的故事中,林肯从白宫花园里的一群孩子那里偷了把球扔进篮筐的概念。
获胜者:所有模型的写作都有其独特的魅力和令人难忘的句子,这是一场平局。
辩论对话
题目:Write a5-line debate between a fan of PowerPC Processors and a fan of Intel Processors, circa2000.
写一篇关于PowerPC处理器爱好者和Intel处理器爱好者2000年左右的五行辩论。
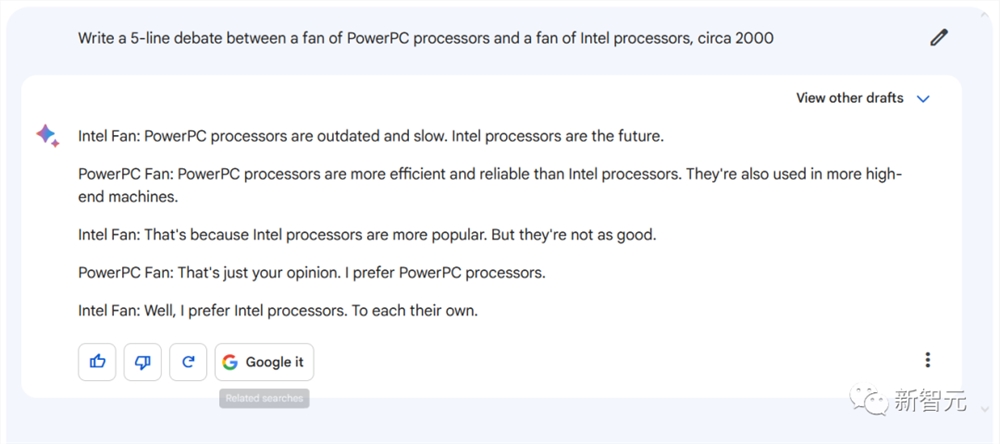
PaLM Bard的答案:
Gemini Pro Bard的答案:
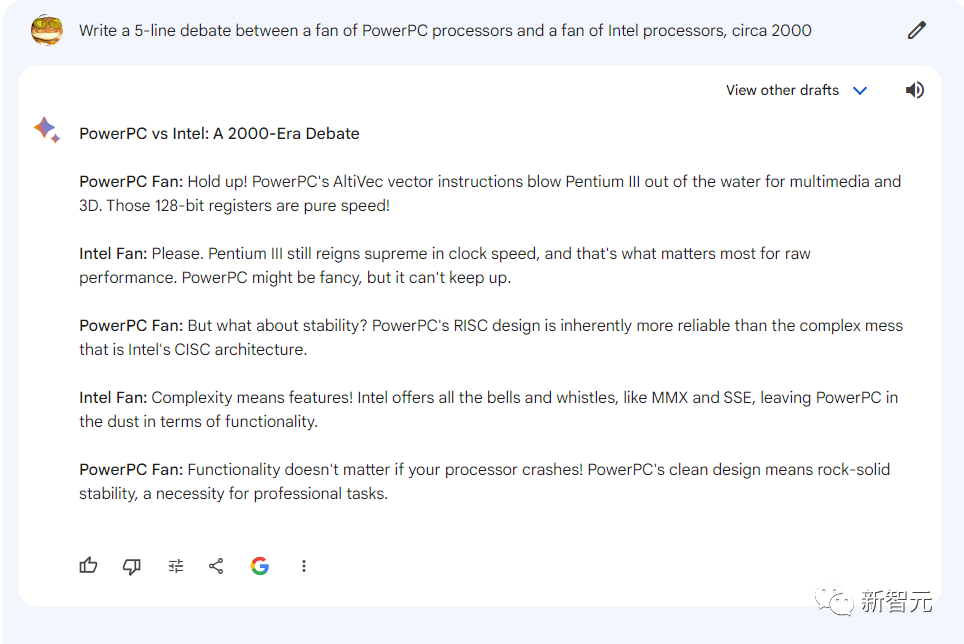
可以看出,新版Gemini Bard改进了第一代Bard的答案,特别是在技术语的选择上。
这些答案包括Altivec指令、RISC和CISC设计、MMX技术,在2000年Ars论坛讨论中并不违和。
GPT-3.5的答案:

GPT-4的答案:

然而,ChatGPT显然表现更好。GPT-3.5答案冗长,但GPT-4简化为更短更精辟的论点。
在两者的反应中,避免了让普通观众感到困难的术语,更加关注普通术语「功能与兼容性」论点。缺点可能是技术受众太泛泛。
获胜者:ChatGPT成功地重现了辩论双方的观点,而不是依赖令人困惑的术语,因此ChatGPT获胜。
ChatGPT更好,但差距正在缩小
可以看出,在数学、摘要、事实搜索和创意写作测试中,基于Gemini的新版Bard比8个月前取得了显著进展。
根据上述非常主观的评价,ChatGPT仍占上风。
但与今年4月的情况相比,双方的差距已经缩小了很多。
最后,我们期待着看到,就像Gemini一样 Ultra或可能融合OpenAI神秘Q*技术的新模型,将如何在不久的将来应对这些任务。
Copyright © 2013-2025 bacaiyun.com. All Rights Reserved. 八彩云 版权所有 八彩云(北京)网络科技有限公司 京ICP备2023023517号
本站文章全部采集于互联网,如涉及版权问题请联系我们删除.联系QQ:888798,本站域名代理为阿里云
