声明:本文来自微信公众号“阿尔法公社”(ID:alphastartups),作者:阿尔法公社,授权站长之家转载发布。
OpenAI和Anthropic是目前融资最多的两家大型创业公司,而这两家公司最大投资者是微软和亚马逊。他们投资的很大一部分不是资本,而是等值的云计算资源。事实上,这两家公司顶尖闭源大模型公司“绑”了科技巨头的“战车”。
除了闭源大模型,还有另一个阵营是开源大模型,MetaAIllama系列就是其中的代表。Meta还牵头组建人工智能联盟(AI Alliance),旨在促进人工智能领域的开源发展,对抗OpenAI、英伟达等人工智能闭源巨头。
大多数使用开源大型模型作为应用程序的初创公司也希望保持自己的独立性,并将使用多云策略,而非常需要一个能力强、成本低的人工智能云平台。
together.人工智能是一家为人工智能初创公司提供培训和推理服务云平台的公司。事实上,它也是一家拥抱开源生态的全栈人工智能公司,拥有自己的模型和数据集,在人工智能底层技术方面积累了深度。
近日,together.Kleinerai获得 1.025亿美元A轮融资由Perkins领投,NVIDIAEmergence Capital等投资者也参加了这一轮,其他投资者也包括NEA、Prosperity7、Greycroft、137Ventures和Lux Capital、Definition Capital、Long Journey Ventures、SCB10x、SV Together种子轮的投资者,如Angel。
除机构外,其种子轮投资者还包括IronPort联合创始人Scotttt Banister、Cloudera联合创始人Jefff Hammerbacher、Oasis Dawnnnnndabs创始人Dabs Song、OpenSea联合创始人Alex Atallah等。本轮融资是公司之前融资规模的五倍,累计融资额为1.2亿美元。
together.联合创始人兼CEOVipulai Ved Prakash说:“如今,培训、微调或产品开源生成人工智能模型极具挑战性。目前的解决方案要求企业在管理大规模基础设施的同时,在人工智能方面拥有重要的专业知识。together.人工智能平台一站式解决了这两个挑战,提供了易于使用和获取的解决方案。我们的目标是帮助创建超越封闭模型的开放模型,并将开源作为整合人工智能的默认方式。”
如果您对人工智能的新浪潮感兴趣,有意见,愿意创业,欢迎扫描代码添加“阿尔法助理”,注明您的“姓名+职位”,并与我们有深入的联系。
苹果前高管和大学教授建立人工智能开源云平台
together.Ai成立于2022年6月,包括Vipul在内的联合创始人 Ved Prakash、Ce Zhang、Chris Re和Percy Liang。
PrakashTopsy此前创立了社交媒体搜索平台,该平台于2013年被苹果收购,随后成为苹果高级总监。
Ce Zhang是苏黎世联邦理工学院计算机科学副教授,领导“分散”人工智能研究。
Percy Liang斯坦福大学计算机科学教授指导学校基础模型研究中心(CRFM)。
Chris Re包括SambaNova在内的多家初创公司共同成立,为人工智能构建硬件和集成系统。
Prakash说:“去年,Chrish说:“、Percy、当Ce和我聚在一起时,我们都清楚地感觉到人工智能基本模型代表了技术的代际变化,这可能是晶体管发明以来最重要的一次。
与此同时,过去几十年在人工智能创新中处于领先地位的开源社区在塑造即将到来的人工智能世界方面的能力有限。
我们可以看到,这些模型倾向于集中在少数公司(OpenAI、Anthropic、Google),这是由于高端GPU集群训练所需的巨大费用。
这就是together.人工智能试图通过创建开放和分散的替代方案来挑战现有的云系统(例如AWS)来改变它。、Azure和Google Cloud),未来的商业和社会将是''至关重要;。
随着企业定义其生成的人工智能战略,他们正在寻找隐私、透明度、定制和部署的便利性。目前的云服务由于其封闭的源模型和数据,无法满足其需求。”
华人类学者与Flashatention技术和Mamba模型一起加入团队首席科学家
今年7月份,Tri 作为首席科学家,Dao加入了公司团队。Tri Dao在斯坦福大学获得计算机科学博士学位,导师是Christopher Ré和Stefano Ermon,他即将成为普林斯顿大学的助理教授。他的研究获得了2022年国际机器学习会议(ICML)亚军奖优秀论文。
Tri Dao还是Flashatention? v2作者,这是一种领先而开源的大语言模型工具,可以加快大语言模型的训练和推理。
FlashAttention-2.大型语言模型(LLMs)NVIDIA的训练和微调速度最多提高了4倍 模型FLOPS利用率在A100上达到72%。
FlashAttention-2.核心注意力操作加速2倍,端到端训练Transformer加速1.3倍。鉴于大型语言模型的培训成本高达数千万美元,这些改进可能节省数百万美元,使模型能够处理上下文的两倍长度。
目前,包括OpenAI在内的各大语言模型公司、Anthropic、Meta和Mistral都在使用Flashatention。
最近,Tri Dao还参与了一个叫做“”的项目Mamba对“选择性状态空间模型”进行了研究(selective state space model)“Mamba在语言建模方面可以与甚至击败Transformer相媲美,并随着上下文长度的增加实现线性扩展,在实际数据中,性能可以提高到百万token长度序列,推理吞吐量可以提高5倍。
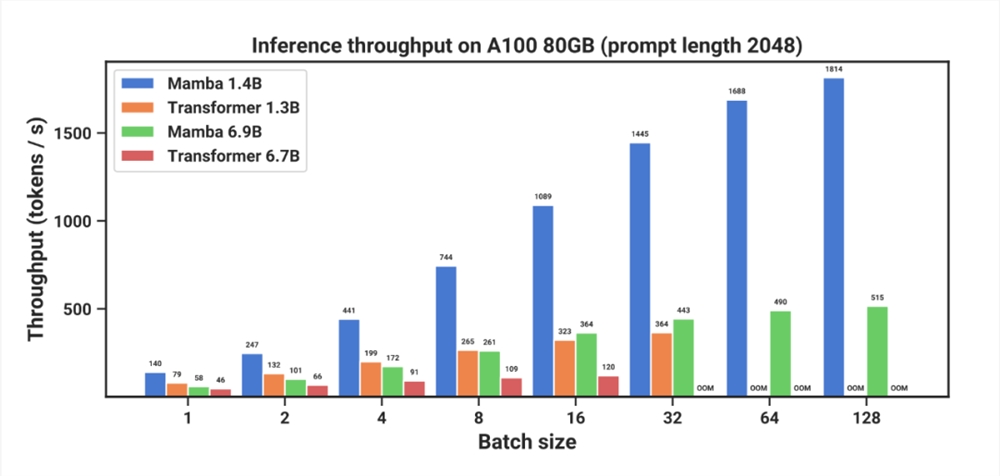
Mamba作为通用序列模型的骨干,在语言、音频和基因组学等模式下实现了SOTA性能。在语言建模方面,无论是预训练还是下游评估,Mamba-3B模型优于同等规模的Transformer模型,可与其规模的Transformer模型相媲美。
在强大的技术团队的支持下,together.除了Flashattentention-2外,ai在推理上也经常创新。他们还使用了Medusa和Flash-Decoding等技术,形成了Transformer模型中最快的推理技术堆栈。通过together推理API,该堆栈允许快速访问100多个开放模型进行快速推理。
关于这笔融资,Kleiner Buckyyperkins合伙人 “人工智能是一个新的基础设施层,改变了我们开发软件的方式。为了最大我们需要让开发者在任何地方使用它。我们预计,随着开源模型的性能接近闭源模型,它们将被广泛使用。together.人工智能使任何组织都能在其基础设施上构建快速可靠的应用程序。”
Together 人工智能种子轮投资者Lux CapitalBrandon Reeves在接受采访时表示:“通过提供跨计算和一流基础模型的开放生态系统,together.Ai正在引领人工智能的“Linux时刻”。together.AI团队致力于打造一个充满活力的开放生态系统,让从个人到企业的任何人都能参与其中。”
不仅有推理速度最快的开源AI云平台,还有自己的数据集和模型
together.Ai不仅仅是AI算力云平台together GPU Clusters,此外,还有专门优化的推理、培训和微调服务。您还可以使用自己的数据集为客户定制人工智能模型,并推出自己的示例开源人工智能模型。
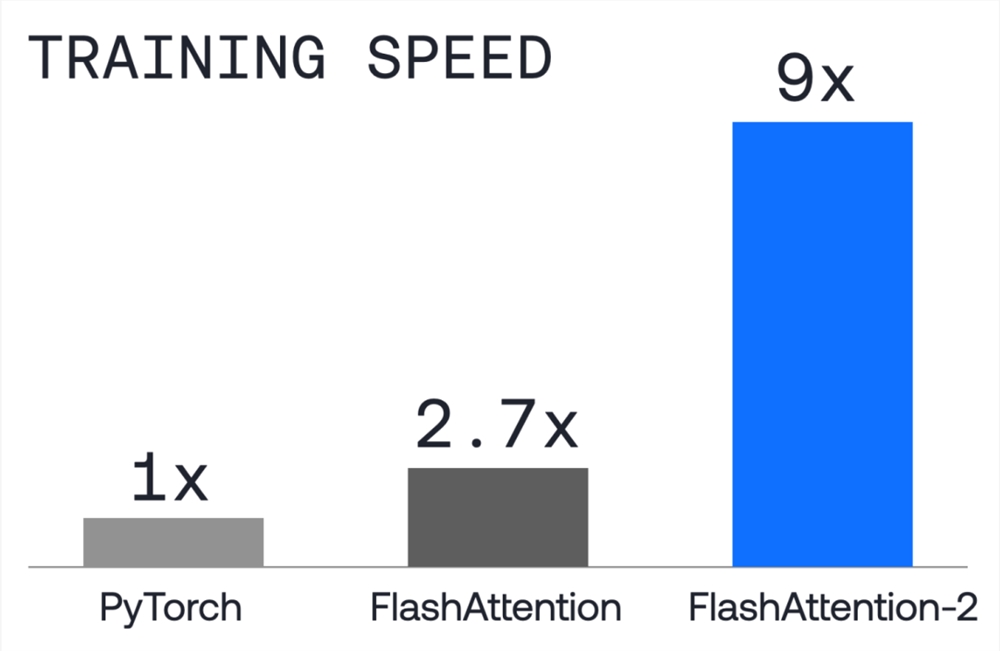
Together GPU Clusters:训练速度比标准Pytorch快9倍
Together GPU Clusters(原名Together Compute)GPU计算能力集群是专门为人工智能模型训练而优化的。它具有极快的模型训练速度和极高成本效率。客户可以在平台上培训和微调模型。
together.Ai为该集群配备了培训软件堆栈,用户可以专注于优化模型质量,而不是调整软件设置。
在速度方面,Flashattention-2的使用速度是标准Pytorch的9倍,成本是AWS的4倍。它使用NVIDIAA100和H100高端GPU。
另外,它还有极佳在可扩展性方面,用户可以选择16个GPU到2048个GPU的计算能力规模,对应不同尺寸的人工智能模型。目前,它还为客户提供专家级支持服务,续订率超过95%。该公司在美国和欧洲建立了初步的数据中心网络,其合作伙伴包括Crusoe Energy和Vultr。
Together Fine-Tuning:使用私有数据进行微调
together.Ai还提供模型微调服务,客户可以使用自己的私人数据微调定制开源模型。together.Ai让用户在微调时完全控制超参数,其平台也与Weights相匹配&Biases对接,让客户的模型微调更加可控透明。
最后,当模型调整完成后,客户可以在平台上托管自己的模型并进行推理。
Together Inference Engine:比TGI或VLLM快3倍
Together Inference Engine(推理引擎)基于NVIDIA的CUDA构建,并在NVIDIA构建 Tensor Core 运行在GPU上。Together团队使用Flashatention-2、Flash-一系列优化推理性能的技术(基本上是开源的),包括Decoding和Medusa,优化了推理性能。
Together推理引擎的速度比其他推理加速框架或服务在同一硬件上运行时快3倍,这意味着基于大型模型的生成人工智能应用程序现在可以提供更快的用户体验、更高的效率和更低的成本。
例如,使用相同的硬件和开源LLM Perf基准测试工具推理Llama-2-70B-Chat模型(500输入Token,150输出Token),测试结果如下图所示。
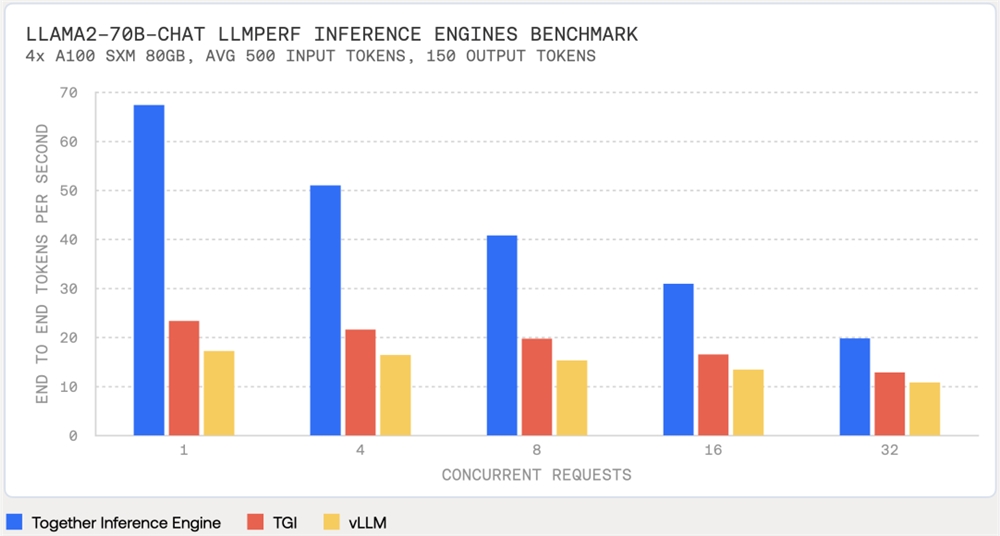
此外,Together推理引擎在速度超快的同时,不会牺牲任何质量。下表显示了几个准确性基准测试的结果。Together推理引擎的结果和参考标志 Face保持一致。

Together Custom Models:使用自由数据加开源数据进行训练
对于企业用户,together.ai还推出了together Custom Models ,本质上,它们可以帮助企业从零开始构建模型,这是一种咨询服务。
他们有专家团队,帮助企业设计和构建基于together的定制人工智能模型的特定工作负荷。.ai的RedPajama-V2数据集(30TTokens)和企业自有的专有数据培训。
开源RedPajama-V2数据集已下载120万次。
together.人工智能将提供训练基础设施和训练技术(FlashAttention-2等)和模型架构(基于Transformer和不基于Transformer)以及训练配方的选择,模型训练后,还提供调整和对齐服务。
模型培训出来后,其所有权完全归因于客户企业,对数据安全非常重要的行业大企业有吸引力;在OpenAI之前的Devday上,他们还推出了基于GPT模型的模型定制服务,正是因为如此。
事实上,toether.除了RedPajama-v2数据集,ai在开源模型中积累了很多,包括GPTT-JT(基于研究小组EleutherAI发布的开源文本生成模型GPT-J-以及OpenChatKit(类似ChatGPT的聊天机器人)。
就客户而言,Pika最近获得了5500万美元的融资 除了Labs,还有Nexusflow、Voyage AI、Cartesia等知名创业公司。
开源生态打破了闭源模型的封闭和权利集中
目前,在人工智能大模型的发展中,特别是基础模型,工业(大工厂、初创公司)明显领先于大学和学术研究机构,闭源大模型在性能上也全面领先于开源大模型。
造成这种差距的主要原因是培训大型模型所需的巨大成本(计算成本、劳动力成本、时间成本),使学校和研究机构只能使用小型模型(6B或7B)参数进行一些相对边缘的研究;或试图扭转现有模式。
闭源大模型超越开源大模型是现实,但如果这种趋势继续下去,人工智能的权利就会越来越集中,形成几个巨头(微软,Google)+几家新巨头(OpenAI+Anthropic)模式。这不利于整个人工智能创业生态的发展。同时,这也是llama2发布时如此震撼的内在原因。
也就是说,together.人工智能的意义。一方面,它们建立了计算能力平台,为企业提供廉价快速的模型培训和推理服务,另一方面,它们也帮助企业建立自己的定制模型,为第三方提供选择空间。
在开源方面,他们还提供了自己的数据集、自己的训练和推理技术栈,以及打破“垄断”的示例开源模型。
而together.人工智能拥有这种能力的原因也与其自身的技术实力密不可分。连续企业家和大学教授的结合使他们不仅知道企业的痛点,而且能够从底层解决和优化。
事实上,这也是一个很好的例子。大学教授拥抱创业精神,利用社会资本进行研究,使他们的研究成果影响更多的人。我们也期待着更多教授/学者+行业人士/持续企业家的创业团队。
Copyright © 2013-2025 bacaiyun.com. All Rights Reserved. 八彩云 版权所有 八彩云(北京)网络科技有限公司 京ICP备2023023517号
本站文章全部采集于互联网,如涉及版权问题请联系我们删除.联系QQ:888798,本站域名代理为阿里云
