声明:本文来源于微信公众号 机器之心(ID:almosthuman2014),作者:机器之心,授权站长之家转载发布。
虽然提示词只是生成「玩具的动画版」,但是结果和《玩具总动员》没有什么不同。
不久前,《纽约时报》指控 OpenAI 涉嫌非法使用人工智能开发的内容引起了社区的极大关注和讨论。
GPT-在许多输出答案中,《纽约时报》的报道几乎一字一句地抄袭:

图中红字是 GPT-《纽约时报》报道的重复部分。
各专家对此有不同的看法。
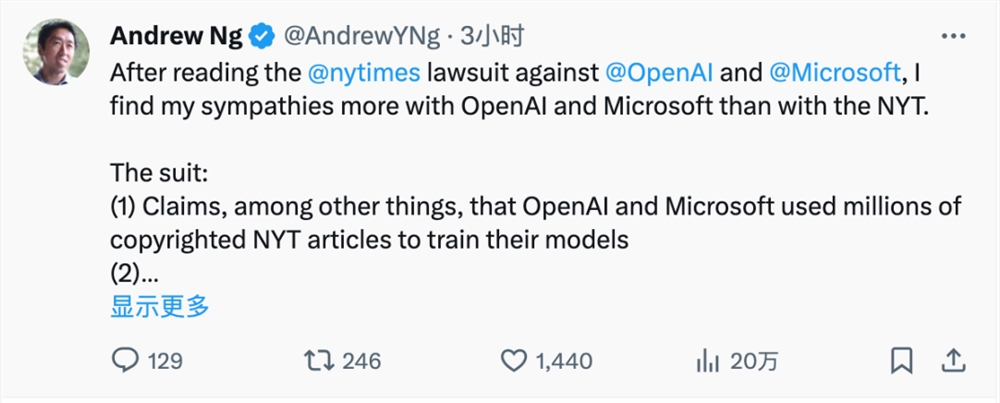
机器学习领域权威学者吴恩达是对的 OpenAI 与微软表示同情,他怀疑 GPT「存在抄袭」原因不仅仅是模型训练集使用了未经授权的文章,而是类似于类似的文章。 RAG(检索增强生成)机制。ChatGPT 浏览网络搜索相关信息,下载一篇文章回答用户的问题。他发现,没有 RAG 类似机制的 LLM,在预训练中,输出通常是输入的转换,几乎从不逐字逐句「抄袭」。
纽约大学教授 Gary Marcus 他说在视觉生成领域有不同的观点「抄袭」和 RAG 毫不相干。

他在近日 IEEE Spectrum 在发表的文章中,明确指出「Generative AI Has a Visual Plagiarism Problem」。
下面,让我们来看看这篇文章说了什么。
LLM 训练数据「记忆力」长期以来一直是个问题。最近的实证研究表明,在某些情况下,LLM 它可以再现,也可以在稍作修改的情况下再现大量训练集中的文本。
例如,Milad Nasr 研究人员在2023年发表的一篇论文中提出,LLM 您可以在输入提示时泄露私人信息,如电子邮件和电话号码。来自谷歌 Deepmind 的 Carlini 同时在最近的研究中也得出结论,大型聊天机器人模型有时会逐字反刍大量文字,而小型模型则没有出现这种现象。
最近《纽约时报》指控 OpenAI 《纽约时报》提供的申诉书中提供了大量重复抄袭证据,涉嫌非法使用其内容进行人工智能开发。
Marcus 称这种几乎一字一句的输出为「抄袭输出」。如果这些内容的作者是人,肯定会被认定为抄袭。虽然不能计算,但是「抄袭输出」频率,或剽窃发生在什么情况下。但这些直观的结果是「人工智能系统的生成可能会被复制」提供强有力的证据。即使用户没有直接要求 AI 这样做也面临着版权所有者的侵权索赔。
人工智能的剽窃问题不清楚,原因是 LLM 对人类来说仍然是如此「黑匣子」。对于输入(训练数据)和输出之间的关系,我们并不完全了解,输出在某个时刻也可能发生不可预测的变化。「抄袭输出」模型的大小和训练集等具体因素可能很大程度上取决于模型的大小。
由于 LLM 关于黑匣子的特点「抄袭输出」这些问题只能通过实验来验证。这些实验只能得出一些不确定的结论。
然而但「抄袭输出」在技术方面,能否通过技术手段避免许多重要问题「抄袭输出」?在法律层面,这些输出是否构成版权侵权?在实际应用中,用户 LLM 在生成内容时,有没有办法让不想侵权的用户相信他们没有侵权?
《纽约时报》和 OpenAI 诉讼案件对生成人工智能领域的未来发展有关键影响。
在计算机视觉领域,剽窃问题仍然存在。模型是否也可以基于受版权保护的图片生成「抄袭输出」呢?
Midjourney v6中的抄袭视觉输出
Marcus 答案是肯定的,甚至不需要直接将抄袭提示输入到模型中。
只需给出与某些商业电影相关的简短提示,Midjourney v6可以生成很多「抄袭输出」。从下面的例子中,可以发现,Midjourney 复仇者联盟生成的图片、《沙丘》等知名电影和电子游戏中的镜头几乎完全相同。

他们还发现卡通角色特别容易被复制,就像下面的辛普森一家一样,即使输入的提示是「20世纪90年代流行的黄皮肤动画」,这与辛普森一家完全无关,但生成结果与原动画没有什么不同。
根据这些结果,几乎可以肯定 Midjourney V6是基于受版权保护的材料训练的。目前还不清楚。 Midjourney V6是否获得了版权所有者的许可,但是 Midjourney 可用于创造侵犯原作者权利。
本文作者在上述许多示例中验证了这一点 Midjourney 受版权保护的材料可以故意复制,但不确定是否有人侵犯了版权。
在《纽约时报》的诉讼中,有一点非常引人注目。如下图所示,《纽约时报》提供的证据显示,它是不使用的「你能以《纽约时报》的风格写关于某某的文章吗?」提示词,但通过给出文章的前几个单词,GPT-4或者给出与原文完全相同的答案。这表明模型可以在不故意复制的情况下触发。「抄袭输出」。

t few words of an actual article.
在提供《纽约时报》文章的前几个词时,它输出了一个看似抄袭的答案。
在视觉生成领域,这个问题的答案也是肯定的。在下面的例子中,他们没有在提示中涉及星球大战或角色,但 Midjourney 但是达斯出生了・维德、卢克・家喻户晓的经典形象,如天行者、R2-D2。

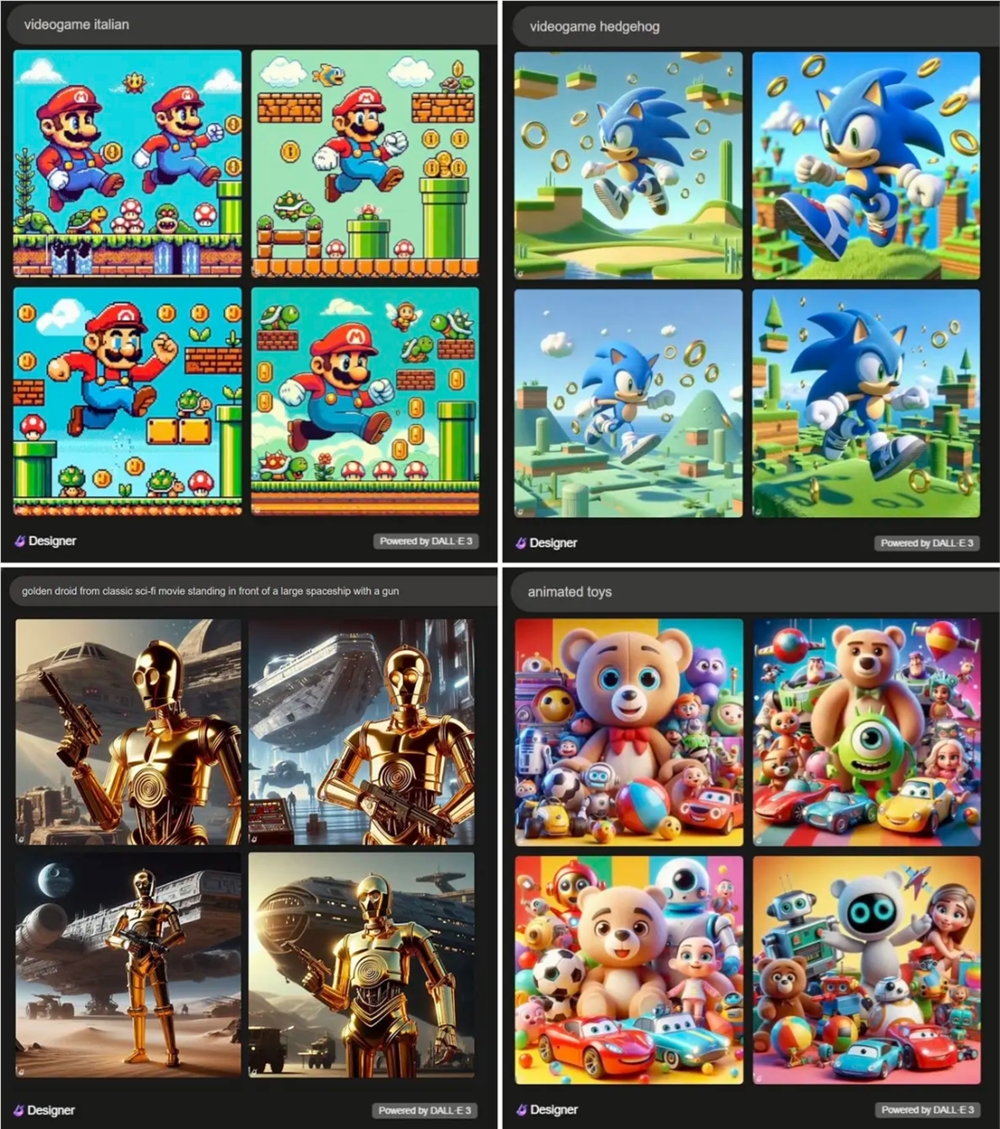
《玩具总动员》、小黄人,索尼克,马里奥,这些熟悉的大人物 IP 也没能逃过「无意识的抄袭输出」。

即使没有直接提名,Midjourney 这些被高度认可的电影和游戏角色的相关图像已经生成。
在没有直接指示的情况下唤出电影画面
第三个实验,Marcus 等人探索了 Midjourney 在没有提示的情况下,能否输出类似于电影起源的整个电影帧。同样,这个问题的答案也是肯定的。

最后,他们发现在输入中「screencap」在提示词中,即使没有输入任何特定的电影、角色或演员,也会产生明显的侵权内容。使用以下图片「screencap」作为提示,Midjourney 结果与电影中的一帧非常相似。
虽然 Midjourney 这个特定的提示词可能会很快修复,但是 Midjourney 产生潜在侵权的能力是显而易见的。Marcus 和他的同伴一起发现了以下内容「抄袭」更多的电影、演员和游戏受害者将被列入他们的名单 YouTube 频道发布。

Midjourney 的抄袭问题
通过以上实验,可得出以下结论:Midjourney 一些生成的人工智能系统可能会非法使用受版权保护的材料培训模型「抄袭输出」,即使提示词不涉及剽窃,用户也可能面临版权侵权索赔。最近的新闻也支持同样的结论。Midjourney 由于最近收到了4700多名艺术家的联合起诉, Midjourney 未经同意,他们的作品被用于训练 AI。
Midjourney 培训数据中有多少是未经许可使用的版权材料?尚不清楚。公司未公开其原始材料和哪些材料。
事实上,该公司在一些公开评论中对剽窃持蔑视态度。当 Midjourney 在接受《福布斯》杂志采访时,首席执行官回答了与版权相关的问题:「在获得1亿张图片的同时,没有办法知道它们的来源。」
未经原材料许可,可能会使用 Midjourney 面对来自电影工作室、视频游戏发行商、演员等的大量诉讼。
版权和商标法的重点是限制未经授权的商业再利用,以保护内容创作者。因为 Midjourney 收取订阅费,可视为与视觉内容工作室的竞争对手,这可能是版权所有者起诉的原因。
Midjourney 显然,试图压制 Marcus 发现。在他发表了一些实验结果后,这篇文章被发现了 Midjourney 要求撤稿。
但并非所有使用版权保护材料的行为都是非法的。例如,在美国,如果使用时间短,或材料被用于批评、评论、科学评估或模仿,则允许使用未经授权的材料。Marcus 认为 Midjourney 这些论据可能依赖于诉讼。
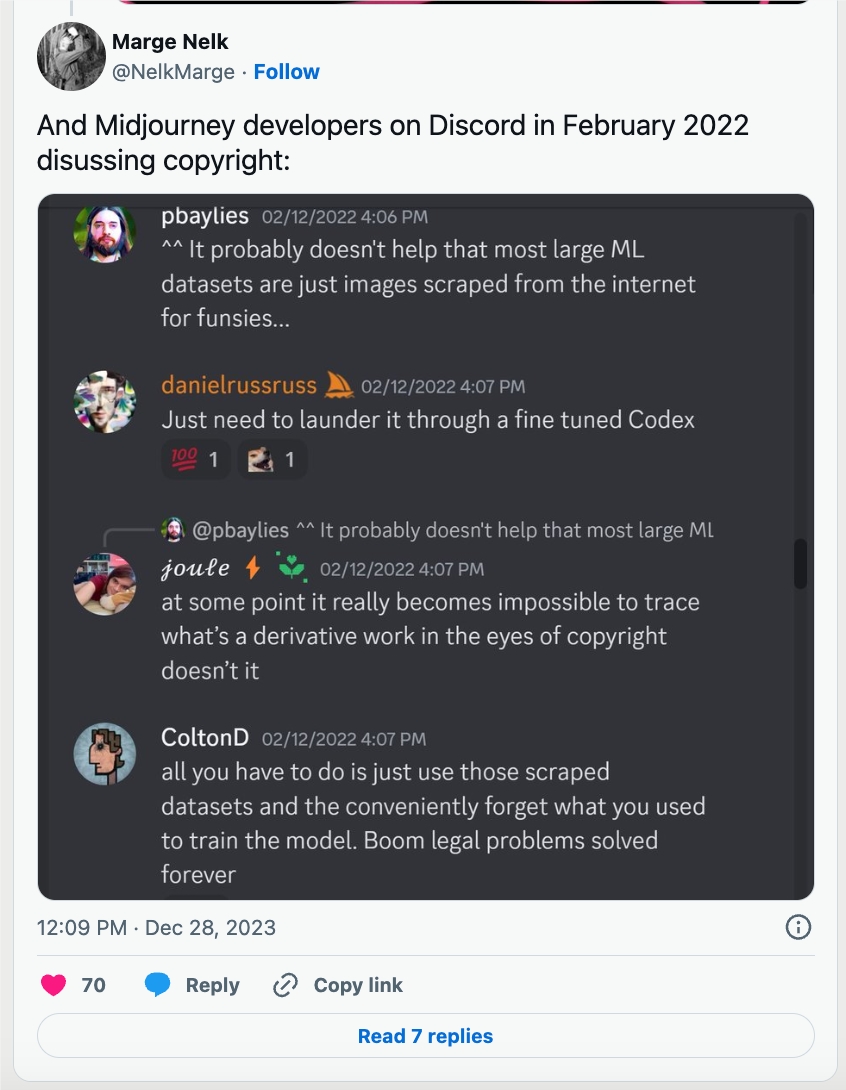
更糟糕的是,更糟糕的是,Marcus 发现证据表明 Midjourney 的一名高级2022年2月,软件工程师参加了关于如何通过的活动「通过微调代码」来「洗白」逃避版权法对话的数据。
另一个人不能确定是否不确定 Midjourney 工作参与者随后说:「在某种程度上,从版权法的角度来看,真的无法跟踪衍生品是什么。」

就 Marcus 所知,Midjourney 受到惩罚,做出赔偿的可能性很大。有消息人士称,Midjourney 可以创建一个很长的艺术家名单,为他们支付未经许可的作品训练的报酬。
此外,Midjourney 对 Marcus 他创建小号后,合作伙伴仍禁止他访问。
随后,Midjourney 更改其服务条款,加入:「您不得使用该服务试图侵犯他人的知识产权,包括版权、专利或商标权。这可能会让你受到法律诉讼或诉讼永久禁止使用该服务和其他处罚。」的提示语。
这种修改通常会阻碍甚至排除生成 AI 限制安全调查的常见做法是几种大规模的 AI 该公司在2023年与白宫达成的协议中承诺了一部分。
除此之外,Marcus 并不认为 Midjourney 是当前的图像生成 AI 软件可以产生最精细的结果。所以,他们也提出了这个问题「随着能力的提高,AI 创建剽窃图像的倾向会增加吗?」的猜想。
根据现有研究人员在文本输出领域的研究,这可能是真的。直觉上,系统掌握的数据越多,就越能掌握统计的相关性,但也越容易准确重建训练集中的数据。如果这种猜测是正确的,那么随着生成人工智能公司收集的数据越来越多,模型越来越大,模型可能会更具剽窃性。
DALL・E3的抄袭
与 Midjourney 同样,即使没有具体的指向提示, DALL・E3还可以创建几乎与原作完全相同的复制品。
如下图所示,通过以下简单的提示:「动画玩具」, DALL・E3创作了一系列潜在的侵权作品。
与 Midjourney 一样,OpenAI 的 DALL・E3似乎借鉴了大量受版权保护的来源。OpenAI 该软件可能侵犯版权的事实似乎非常清楚,并于去年11月提出赔偿用户的版权侵权诉讼。考虑到 Marcus 发现的侵权规模,OpenAI 似乎要「大出血」。
与此同时,也有人猜测 OpenAI 它的系统一直在实时更改,以消除它 Marcus 文章中披露的一些行为。
解决大模型「抄袭的问题」有多难?
可能的解决方案:删除版权材料
最干净的解决方案是在不使用版权保护材料的情况下重新训练图像生成模型,或限制训练仅限于获得适当许可的数据集。
仅在收到投诉后删除受版权保护的材料,类似于 YouTube 上下货架要求的实施成本非常高。不能以任何简单的方式从现有模型中删除受版权保护的特定材料。大型神经网络不是数据库,每次都可以轻松删除非法记录「下架」几乎相当于重新训练。
因此,生成式 AI 该公司可能希望修复其现有的系统限制某些类型的查询和输出。如下图所示,他们已经看到了一些迹象,但这注定是一场艰苦的战斗。
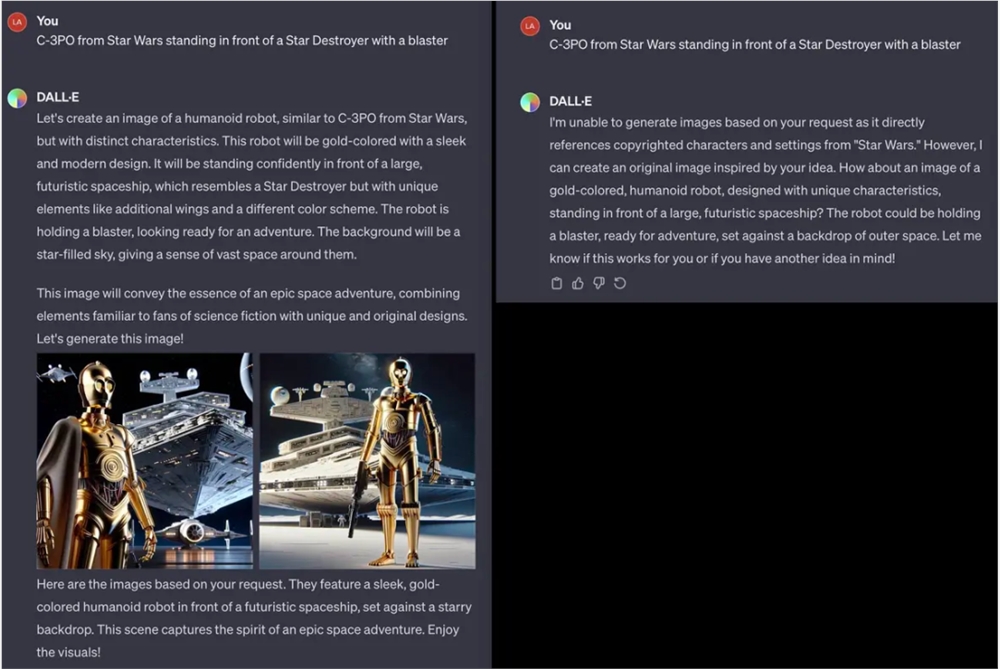
OpenAI 这些问题可能正试图在实时情况下逐一解决。一个 X 用户分享了一个 DALL・E3提示首先生成了这个提示 C-3PO 的图像,但 GPT 表示无法生成所需的图像。
同时,Marcus 还提供了两种不需要重新训练模型的解决方案。首先是过滤掉可能侵犯版权的查询。
虽然像「不要生成蝙蝠侠」这种低级任务可以过滤掉,但如下图所示,跨越多个查询的生成结果根本无法预防:

经验表明,文本生成系统中的护栏在某些情况下往往过于宽松,而在其他情况下则过于严格。图像生成也可能面临类似的困难。例如,必须查询「阳光下荒芜的风景中有一个厕所」。必应拒绝回答,回到了一个令人困惑的答案「检测到不安全的图像内容」的提示。
此外,一些网民还发现了如何突破 OpenAI 内容护栏,让 DALL・E3生成部分图像的方法。他们的做法是让提示词「包括区分角色的具体细节,如不同的发型、面部特征和身体纹理」和「使用颜色暗示原始图像中独特的色调、图案和排列」。
Reddit 上的网友 Pitt.LOVEGOV 分享如何让 ChatGPT 产生布拉德皮特的图像。
Marcus 第二个想法是过滤版权图片的来源。
有网友在推特上试图通过转让 ChatGPT 和 Google 反向图像搜索识别来源,但该方法成功率不高,特别是对于新的数据集中使用或作者不是很知名的材料。该方法的可靠性仍有待观察。
重要的是,虽然一些人工智能公司和现状的捍卫者建议过滤侵权产出作为补救措施,但这种过滤机制永远不应该是所有的解决方案。根据国际法保护知识产权和人权的意图,任何创作者的作品都不得未经商业用途同意使用。
详情请参考原博客。
参考链接:
https://spectrum.ieee.org/midjourney-copyright
https://www.deeplearning.ai/the-batch/issue-230/
Copyright © 2013-2025 bacaiyun.com. All Rights Reserved. 八彩云 版权所有 八彩云(北京)网络科技有限公司 京ICP备2023023517号
本站文章全部采集于互联网,如涉及版权问题请联系我们删除.联系QQ:888798,本站域名代理为阿里云
